Deploying a Big Data Ecosystem: Dockerized Hadoop, Spark, Hive, and Zeppelin
Post by
Administrator
Published
26 Tháng 1, 2025
Deploying a Big Data Ecosystem: Dockerized Hadoop, Spark, Hive, and Zeppelin

The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. The Minimum Hadoop cluster consists of Hadoop Common to support the other modules, such as Hadoop Distributed File System (HDFS) as distributed storage, Hadoop YARN to schedule and manage the cluster, and Hadoop MapReduce as an execution engine to do the parallel processing.
Spark, on the other hand, is an alternative execution engine for processing data. The key difference is that Spark uses Resilient Distributed Datasets (RDDs) and stores them in memory, resulting in significantly better performance than MapReduce. Spark can run standalone for basic functionalities. However, when used with Hadoop, Spark can leverage Hadoop’s features for cluster management, fault tolerance, security, and more.
Hive is an analytical tool that leverages data stored in HDFS and uses Spark or MapReduce as its execution engine. This allows users to analyze data using familiar SQL statements, making it easier for developers to find insights from the data.
Why do we need to run it in docker mode?
Understanding how the system works internally (under the hood) is necessary. This knowledge can be valuable for testing tuned configurations or new features. In these cases, a sandbox or development system is ideal for its ease of setup and lower cost.
However, a mature, Dockerized ecosystem can also be used in production environments. This approach simplifies deployment automation and enables cluster autoscaling functionality.
In this article, We will try to spin up Hadoop with docker mode using Dockerfile. It will consist of Hadoop, Spark, Hive, and Zeppelin.
Environment Used
Host
- macOS 14.3
- Apple M1 chip
- 16 GB of memory
Docker
- Docker Version: 25.0.5
- Docker Compose Version: 2.22.0
- Orbstack Version: 1.5.1
- Hadoop image: apache/hadoop:3
- MySQL image: mysql:latest
- [Optional] Firefox image: jlesage/firefox:latest
- [Optional] Custom Hadoop image: bayuadiwibowo/hadoop-namenode:latest
Hadoop Base
We will use Docker Compose to build the image and run the container.
Directory Structure
hadoop % ls -l
-rw-r--r-- 1 user1 staff 1764 Oct 1 13:25 config
-rw-r--r-- 1 user1 staff 751 Oct 1 13:04 docker-compose.yaml
docker-compose.yaml
This .yaml configuration will spin a Hadoop base cluster with 2 data nodes.
version: "2"
services:
namenode:
image: apache/hadoop:3
hostname: namenode
volumes:
- ./Makefile:/opt/hadoop/Makefile
ports:
- 9870:9870
env_file:
- ./config
environment:
ENSURE_NAMENODE_DIR: "/tmp/hadoop-root/dfs/name"
command: ["hdfs", "namenode"]
datanode_1:
image: apache/hadoop:3
command: [ "hdfs", "datanode" ]
env_file:
- ./config
datanode_2:
image: apache/hadoop:3
command: [ "hdfs", "datanode" ]
env_file:
- ./config
resourcemanager:
image: apache/hadoop:3
hostname: resourcemanager
command: [ "yarn", "resourcemanager" ]
ports:
- 8088:8088
env_file:
- ./config
volumes:
- ./test.sh:/opt/test.sh
nodemanager:
image: apache/hadoop:3
command: [ "yarn", "nodemanager" ]
env_file:
- ./config
firefox:
image: jlesage/firefox
hostname: firefox
ports:
- 5800:5800
Notes:
firefoxused for easier access to all Hadoop UIs. Sincefirefoxin the same network as Hadoop, it can access all Hadoop container ports without any port forwarding.
config
This config file helps us set the environment variables used by the container.
HADOOP_HOME=/opt/hadoop
CORE-SITE.XML_fs.default.name=hdfs://namenode
CORE-SITE.XML_fs.defaultFS=hdfs://namenode
HDFS-SITE.XML_dfs.namenode.rpc-address=namenode:8020
HDFS-SITE.XML_dfs.replication=1
MAPRED-SITE.XML_mapreduce.framework.name=yarn
MAPRED-SITE.XML_yarn.app.mapreduce.am.env=HADOOP_MAPRED_HOME=$HADOOP_HOME
MAPRED-SITE.XML_mapreduce.map.env=HADOOP_MAPRED_HOME=$HADOOP_HOME
MAPRED-SITE.XML_mapreduce.reduce.env=HADOOP_MAPRED_HOME=$HADOOP_HOME
YARN-SITE.XML_yarn.resourcemanager.hostname=resourcemanager
YARN-SITE.XML_yarn.nodemanager.pmem-check-enabled=false
YARN-SITE.XML_yarn.nodemanager.delete.debug-delay-sec=600
YARN-SITE.XML_yarn.nodemanager.vmem-check-enabled=false
YARN-SITE.XML_yarn.nodemanager.aux-services=mapreduce_shuffle
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-applications=10000
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-am-resource-percent=0.1
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.queues=default
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.capacity=100
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.user-limit-factor=1
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.maximum-capacity=100
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.state=RUNNING
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_submit_applications=*
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_administer_queue=*
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.node-locality-delay=40
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings=
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings-override.enable=false
Starting Cluster
hadoop % docker-compose up -d
UIs Check
Open the firefox by accessing http://localhost:5800/. Try to access these UIs from the firefox.
- Namenode UI: http://namenode:9870/
- ResourceManager UI: http://resourcemanager:8088/
Submit Sample Job
To test the Hadoop cluster, we can submit a MapReduce sample job. SSH access the Namenode with docker exec command and submit a sample job with yarn command.
hadoop % docker exec -ti hadoop-namenode-1 /bin/bash
namenode % yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-HADOOP_VERSION.jar pi 10 15
Number of Maps = 10
Samples per Map = 15
...
...
Job Finished in 37.678 seconds
Estimated value of Pi is 3.17333333333333333333
Notes:
- Replace
HADOOP_VERSIONJAR with available version under theshare/hadoop/mapreducedirectory. - Find the detailed job information from the Namenode UI.
Stopping Cluster
hadoop % docker-compose down
Add Spark to Namenode
MapReduce is the default execution engine of Hadoop. Installing Spark is necessary to be able to submit a Spark job. Add and edit the following files and rebuild the cluster with docker-compse up command.
Directory Structure
hadoop % ls -l
-rw-r–r-- 1 user1 staff 1764 Oct 1 13:25 Makefile
-rw-r–r-- 1 user1 staff 1764 Oct 1 13:25 config
-rw-r–r-- 1 user1 staff 751 Oct 1 13:04 docker-compose.yaml
docker-compose.yaml
version: "2"
services:
namenode:
image: apache/hadoop:3
hostname: namenode
volumes:
- ./Makefile:/opt/hadoop/Makefile
ports:
- 9870:9870
env_file:
- ./config
environment:
ENSURE_NAMENODE_DIR: "/tmp/hadoop-root/dfs/name"
command: bash -c "sudo yum install -y make && sudo make install-spark && make install-python3 && make start-namenode"
datanode_1:
image: apache/hadoop:3
command: [ "hdfs", "datanode" ]
env_file:
- ./config
datanode_2:
image: apache/hadoop:3
command: [ "hdfs", "datanode" ]
env_file:
- ./config
resourcemanager:
image: apache/hadoop:3
hostname: resourcemanager
command: [ "yarn", "resourcemanager" ]
ports:
- 8088:8088
env_file:
- ./config
volumes:
- ./test.sh:/opt/test.sh
nodemanager:
image: apache/hadoop:3
command: [ "yarn", "nodemanager" ]
env_file:
- ./config
firefox:
image: jlesage/firefox
hostname: firefox
ports:
- 5800:5800
Notes:
- The bolded text highlights the differences.
Makefile
install-spark:
sudo wget https://archive.apache.org/dist/spark/spark-3.5.0/spark-3.5.0-bin-hadoop3.tgz --no-check-certificate
mkdir /opt/spark
mv spark-3.5.0-bin-hadoop3.tgz /opt/spark/
tar -zxvf /opt/spark/spark-3.5.0-bin-hadoop3.tgz -C /opt/spark
install-python3:
sudo yum install -y python3
sudo unlink /usr/bin/python
sudo ln -s /usr/bin/python3 /usr/bin/python
start-namenode:
hdfs namenode
Submit Spark Job
hadoop % docker exec -ti hadoop-namenode-1 /bin/bash
namenode % /opt/spark/spark-3.5.0-bin-hadoop3/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
/opt/spark/spark-3.5.0-bin-hadoop3/examples/jars/spark-examples_2.12-3.5.0.jar
Zeppelin Notebook
A web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala, Python, R, etc.
Zeppelin will be added to the Namenode, download the tarball installer from https://zeppelin.apache.org/download.html. Extract the installer using these commands.
hadoop % docker exec -ti hadoop-namenode-1 /bin/bash
namenode % tar zxvf zeppelin-0.11.0-bin-all.tgz
namenode % mv zeppelin-0.11.0-bin-all /opt/zeppelin
namenode % cp /opt/zeppelin/conf/zeppelin-env.sh.template /opt/zeppelin/conf/zeppelin-env.sh
zeppelin-env.sh
Edit the following configurations.
export JAVA_HOME=/usr/lib/jvm/jre/
export ZEPPELIN_ADDR=0.0.0.0
export SPARK_HOME=/opt/spark/spark-3.5.0-bin-hadoop3
Interact with Daemon
namenode % /opt/zeppelin/bin/zeppelin-daemon.sh start
namenode % /opt/zeppelin/bin/zeppelin-daemon.sh status
namenode % /opt/zeppelin/bin/zeppelin-daemon.sh stop
Accessing the UI
Open the firefox by accessing http://localhost:5800/. Try to access http://namenode:8080/ from the firefox.
Reading HDFS File with Zeppelin
We will try to read a CSV file as a Spark Dataframe from the HFDS. You can use your own CSV file or use these sample files.
namenode % mkdir /opt/sample_data
namenode % cd /opt/sample_data
namenode % wget https://raw.githubusercontent.com/metatron-app/metatron-doc-discovery/master/_static/data/sales-data-sample.csv
Use these commands to create a directory and copy data to the HDFS.
namenode % hadoop fs -mkdir /sample_data
namenode % hadoop fs -put /opt/sample_data/sales-data-sample.csv /sample_data/
Access the Namenode UI via the 9870 port to confirm the file is successfully copied.
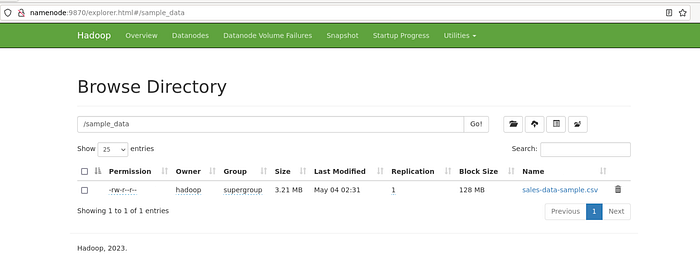
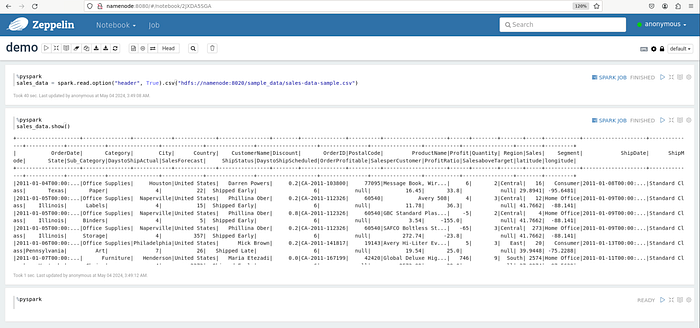
Use this code snippet to read CSV files from HDFS as Spark Dataframe.
sales_data = spark.read.option("header", True).csv("hdfs://namenode:8020/sample_data/sales-data-sample.csv")
sales_data.show()
Enable Hive
Similar to the zeppelin, Hive will be installed on the Namenode. First, we need to download the installer from https://hive.apache.org/general/downloads/. We will use this version of hive https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz.
Extract the installer and move it to /opt/hive directory.
namenode % tar zxvf apache-hive-3.1.3-bin.tar.gz
namenode % mv apache-hive-3.1.3-bin /opt/hive
MySQL Hive Metastore Preparation
MySQL will be used as the Hive Metastore database (HMS). In short explanation, HMS will store all Hive metadata to link between HDFS files to the Hive table. Play around with the Documentation for detailed information.
Edit the existing docker-compose file to add the MySQL container and spawn the container with docker-compose upcommand.
docker-compose.yaml
version: "2"
services:
hive_metastore:
image: mysql
command: --default-authentication-plugin=mysql_native_password
restart: always
environment:
MYSQL_ROOT_PASSWORD: password
namenode:
image: apache/hadoop:3
hostname: namenode
volumes:
- ./Makefile:/opt/hadoop/Makefile
ports:
- 9870:9870
env_file:
- ./config
environment:
ENSURE_NAMENODE_DIR: "/tmp/hadoop-root/dfs/name"
command: bash -c "sudo yum install -y make && sudo make install-spark && make install-python3 && make start-namenode"
datanode_1:
image: apache/hadoop:3
command: [ "hdfs", "datanode" ]
env_file:
- ./config
datanode_2:
image: apache/hadoop:3
command: [ "hdfs", "datanode" ]
env_file:
- ./config
resourcemanager:
image: apache/hadoop:3
hostname: resourcemanager
command: [ "yarn", "resourcemanager" ]
ports:
- 8088:8088
env_file:
- ./config
volumes:
- ./test.sh:/opt/test.sh
nodemanager:
image: apache/hadoop:3
command: [ "yarn", "nodemanager" ]
env_file:
- ./config
firefox:
image: jlesage/firefox
hostname: firefox
ports:
- 5800:5800
Access MySQL and create metastore_db database, it will store all metadata of the Hive.
mysql> CREATE DATABASE metastore_db;
mysql> USE metastore_db;
mysql> GRANT all on *.* to root;
Hive Configuration
Since MySQL is used as the Metastore, we need to provide the connector for Hive. Download the JAR connector and put it in the Hive library directory.
namenode % wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.28/mysql-connector-java-8.0.28.jar
namenode % mv mysql-connector-java-8.0.28.jar /opt/hive/lib/
hive-env.sh
Copy hive-env.sh.template to hive-env.sh under conf directory and edit with the following values.
HADOOP_HOME=/opt/hadoop
HIVE_CONF_DIR=/opt/hive/conf
hive-site.xml
Copy hive-default.xml.template to hive-site.xml and edit the following values.
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hive_metastore/metastore_db?useConfigs=maxPerformance</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the
connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/tmp/${user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/tmp/${user.name}</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
<description>
Setting this property to true will have HiveServer2 execute
Hive operations as the user making the calls to it.
</description>
Add HIVE_HOME to the environment variable and add the executable binary file to the system.
namenode % export HIVE_HOME=/opt/hive
namenode % export PATH=$PATH:$HIVE_HOME/bin
For the first installation, we need to initialize the database schema with the following command.
namenode % schematool -initSchema -dbType mysql
Next, we need to prepare directories and access permission to the HDFS. This directory will store the physical data of the Hive tables.
namenode % hdfs dfs -mkdir -p /user/hive/warehouse
namenode % hdfs dfs -mkdir -p /tmp/hive
namenode % hdfs dfs -chmod 777 /tmp/
namenode % hdfs dfs -chmod 777 /user/hive/warehouse
namenode % hdfs dfs -chmod 777 /tmp/hive
Now we can serve the Hiveserver2 service and start to use the Hive.
namenode % hive --service hiveserver2 &
Accessing Hive from Zeppelin
There is no hive default interpreter provided by the Zeppelin. We need to create a new interpreter from the JDBC group and adjust the driver to Hive. Create a new interpreter from the JDBC group and set the following values.
default.url = jdbc:hive2://namenode:10000
default.user = Keep blank/empty
default.password = keep blank/empty
default.driver = org.apache.hive.jdbc.HiveDriver
Next, we need to provide the Hive driver library for the newly created interpreter.
namenode % cp /opt/hadoop/share/hadoop/common/hadoop-common-3.3.6.jar /opt/zeppelin/interpreter/jdbc/
namenode % ln -s /opt/hive/lib/*.jar /opt/zeppelin/interpreter/jdbc/
namenode % /opt/zeppelin/bin/zeppelin-daemon.sh restart
Now, let’s start using the Hive!!!
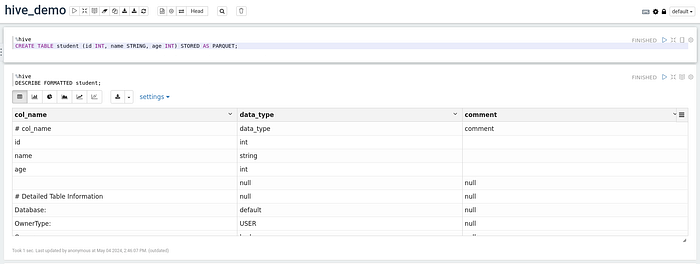

That’s it!!! 🏁 🏁 🏁
Now, we can play around with the Hadoop ecosystem and try to understand how under the hood all tools work together. Stay tuned for the sample pipeline to ingest data from CDC (maybe) to the Hive table and build a simple query transformation!
Related repository: https://github.com/bayuadiwibowo/docker/tree/master/hadoop
Thank you! 🍻